
Large Language Model Operations (LLMOps) are a term you may be familiar with. LLMOps presents tools and best practices to aid in the lifecycle management of LLMs and LLM-powered applications. In this piece, I’ll describe how LLMOps differ from MLOps and how LLMs will affect the adoption of Generative AI.
How Are Large Language Models (LLMs) Used In Organizations?
Training groundwork LLMs, such as GPT, Claude, Titan, and LLaMa, can be expensive. Most organizations need more substantial money, advanced infrastructure, and seasoned machine learning knowledge to train foundation models and make them viable for developing Generative AI-powered systems. Many firms look for cheaper ways to include LLMs in their operations rather than training a foundation model. Each option, however, requires a well-defined methodology and the appropriate tools to assist creation, deployment, and maintenance.
Prompt Engineering
Prompt engineering is the clever development of text inputs called prompts that guide an LLM toward creating the desired result. Techniques such as few-shot and chain-of-thought (CoT) prompts enhance the accuracy and response quality of the model. This simple method allows companies to interact with LLMs via API calls or user-friendly platforms like the ChatGPT online interface.
Fine-tuning
Transfer learning is comparable to this method. Fine-tuning a pre-trained LLM for a specific use case entails training it on domain-specific data. Fine-tuning boosts the model’s output and reduces hallucinations (logically correct but incorrect replies). Although the early costs of fine-tuning may be higher than prompt engineering, the benefits become evident throughout inference. By fine-tuning a model with proprietary data from a business, the resultant prompts during inference are more concise and use fewer tokens. This increases model efficiency, accelerates API answers, and lowers backend expenses. One example of fine-tuning is ChatGPT. While GPT is the base model, ChatGPT is a fine-tuned counterpart designed to create text in a conversational form.
Retrieval Augmented Generation (RAG)
RAG, also known as knowledge or prompt augmentation, extends prompt engineering by augmenting prompts with data from external sources such as vector databases or APIs. This information is put into the prompt before sending it to the LLM. Without substantial model fine-tuning, RAG is a less expensive technique to enhance the factual dependability of models.
What Is LLMOps (Large Language Model Operations)?
LLMs like ChatGPT have emerged as game-changing tools in the constantly growing artificial intelligence (AI) realm. On the other hand, anyone who has worked on AI systems employing LLMs understands the unique obstacles of moving from a proof of concept in a local Jupyter Notebook to a full-fledged production system. LLMs present new challenges in creation, deployment, and maintenance. As these language models get more complicated and large, the need for efficient and simplified processes becomes more critical. This is where LLMOps comes into play. LLMOps, as a subset of MLOps, is responsible for supervising the lifecycle of LLMs, from training to maintenance, employing cutting-edge tools and processes. LLMOps promises to make the route to Generative AI adoption easier by operationalizing technologies at scale.
How Does LLMOps Manage A Large Language Model’s Lifecycle?
LLMOps provides developers with the tools and best practices they need to manage the lifecycle of LLMs. Although many features of LLMOps are similar to MLOps, foundation models need the development of new techniques, standards, and tools. Let’s look at the LLM lifecycle focusing on fine-tuning because organizations need to train LLMs from the start.
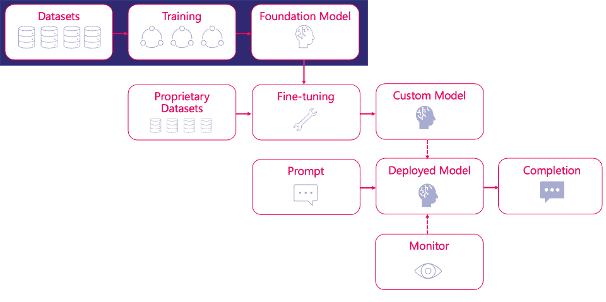
You begin the fine-tuning procedure with an already-trained base model. The bespoke model is then trained on a more specific, smaller dataset. Prompts are sent in when this custom model is deployed, and the necessary completions are returned. Monitoring and retraining the model to maintain consistent performance is critical, especially in AI systems powered by LLMs. By combining prompt management, LLM chaining, monitoring, and observability approaches not often seen in ordinary MLOps, LLMOps make applying LLMs easier.
Prompt Management
People interact with LLMs mostly through prompts. Anyone who has created a prompt knows that improving it is a time-consuming process that requires multiple efforts to achieve a decent result. LLMOps tools often provide facilities for tracking and versioning prompts and their outputs over time. This makes determining the model’s overall effectiveness easy. Certain platforms and tools also allow you to rapidly compare prompts across several LLMs, allowing you to locate the best-performing LLM for your prompt.
LLM Chaining
LLM chaining connects many calls in sequence to provide a unique application functionality. The output of one LLM call serves as the input for the next LLM call in this cycle, culminating in the ultimate result. This design method presents a novel way for AI application design by breaking difficult tasks into smaller phases. For example, instead of using a single lengthy prompt to create a short narrative, you may divide the prompt into shorter prompts for specific subjects and get more accurate results. Chaining overcomes the intrinsic limitation of the maximum amount of tokens an LLM may handle simultaneously. LLMOps simplifies chain management by combining chaining with additional document retrieval techniques, such as using a vector database.
Monitoring And Observability
An LLM observability system collects real-time data points after model deployment to detect probable model performance decline. Real-time monitoring allows for the early detection, intervention, and rectification of performance issues before they impact end users. An LLM observability system collects many data points.
- Prompts.
- Prompt tokens/length.
- Completions.
- Completion tokens/length.
- Unique identifier for the conversation.
- Latency.
- Step in the LLM chain.
- Custom metadata.
A well-structured observability system that records prompt-completion pairings regularly can identify when changes like retraining or modifying foundation models start to impair performance. Monitoring models for drift and bias are also critical. While drift is a common problem in traditional machine learning models, monitoring with LLMs is much more critical due to their reliance on foundation models. Bias can arise from the initial data sets on which the foundation model was trained, private datasets used in fine-tuning, or even human assessors rating prompt completions. A robust review and monitoring mechanism is required to properly address bias.
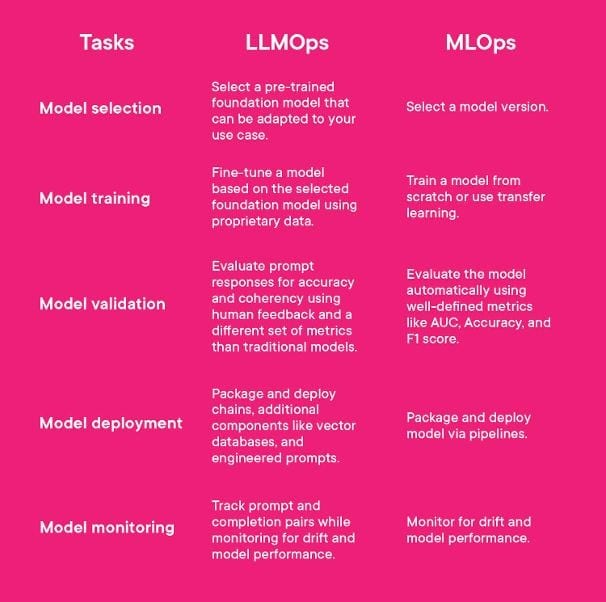
What Are The Key Differences Between LLMOps And MLOps?
It is evident that LLMOps is the MLOps counterpart for LLMs if you have read this far. You’ve realized that LLMOps is critical to managing LLMs, particularly fine-tuned LLMs you’ve trained. While LLMOps and MLOps have many similarities, it is useful to examine their differences by examining the usual jobs in the machine learning lifecycle.
What Are The Prospects For LLMs And LLMOps?
The fast innovation of LLMOps tools and frameworks makes forecasting the technology’s direction even a month, much alone a year, difficult. One thing is certain: LLMOps pave the road for organizations to use LLMs. LLMs are changing how we design AI-powered systems and making machine learning more accessible, reducing AI to a simple prompt or API request. We are only now beginning to understand the potential of LLMs in tackling business difficulties and simplifying processes as Generative AI advances. LLMOps is the best approach to continuously monitor and enhance the performance of LLMs, resulting in faster resolution of performance issues and happier clients. I’m excited to see how LLMOps evolves in the following months and if it will survive or evolve into something else!


